Disseny
- Tècniques per a la solució de problemes
- Bones pràctiques per escriure codi
- És dolent el teu codi?
- Principis generals de programació
- Principis de POO (SOLID)
- Dependències a POO
- Arquitectura i fronteres
- REST APIs
- Referències
Tècniques per a la solució de problemes
-
Definir el problema: el punt de partida i l’objectiu
- si el problema te l’ha donat un altre, explica’l amb les teves paraules
- representa el problema amb dibuixos i diagrames
- identifica les coses que no saps
-
Idear un pla
- Descomposició: trencar un problema en parts més senzilles (estructura d’arbre)
- Generalització: abstracció, identificar patrons i reduir el nombre de conceptes
- Patrons senzills: noms: objectes; verbs: operacions; adjectius: propietats; números: variables
- Patrons de control: bucles, subrutines, regles
- Altres tècniques:
- Pensament crític: posa en dubte les teves decisions… i si falla?
- Resoldre un problema concret
- Troba un problema relacionat
- Cercar cap enrere des de l’objectiu… com puc arribar?
- Dissenyar un model (simplificació, representació, dades, interacció)
-
Executar el pla
-
Revisar i estendre (iteració)
Bones pràctiques per escriure codi
Estàs escrivint codi per llegir-lo en el futur, o bé per un altre…
- Les classes han de ser petites, per sota de 500 línies, i han de tenir un nombre limitat de mètodes
- Els mètodes han de ser petits, per sota de 30 línies, i han de fer una feina concreta
- Has d’escriure el codi perquè s’expliqui a ell mateix, però on no arribis, utilitza comentaris
- No facis línies massa llargues, com a molt de 120 caràcters
- Manté baix el nivell de sagnat del codi, i intenta no superar els 3-4 nivells
- Si hi ha dades d’entrada, crea-les des del codi per no haver d’introduir-les des del teclat
- Anomena les classes, els mètodes i les variables amb els criteris ja explicats
- Decideix el teu estil i segueix-lo de forma consistent
És dolent el teu codi?
- És massa rígid? Es poden canviar els detalls interns d’aquest mòdul en el futur sense tocar el codi d’altres mòduls i altres capes? El codi rígid és el que té dependències que serpentegen en tantes direccions que no es pot fer un canvi aïllat sense canviar-ho tot al voltant.
- És massa fràgil? Seria difícil trobar llocs on fer canvis i refactoritzar en el futur? El codi fràgil es trenca de formes estranyes i que no es poden predir.
- Hauria de ser una característica reutilitzable? Si ho fos, el codi depèn de mòduls no desitjats que es podrien evitar? Vols una banana, però el que obtens és un goril·la agafant-la i tota la jungla amb ell.
Si mirem de prop, el fil conductor dels tres problemes esmentats és l’acoblament. Els mòduls depenen els uns dels altres de maneres no desitjades i resulten en un codi espagueti.
El codi hauria d’estar desacoblat entre els mòduls i les capes. Les polítiques d’alt nivell i les abstraccions no haurien de dependre de detalls de baix nivell, sinó d’abstraccions: caldria invertir la dependència dels mòduls als llocs necessaris. I escriure classes que només fan una cosa i només tenen un motiu per canviar.
El codi bo hauria d’explicar què està fent. Hauria de ser avorrit de llegir. Tot hauria de ser perfectament obvi. Això és bon codi - Robert Martin.
Principis generals de programació
- DRY (Don’t repeat yourself): no et repeteixis.
- Principi de l’abstracció: cada peça significant s’ha d’implementar en només un lloc del codi font.
- KISS (Keep it simple): mantenir la senzillesa.
- Evita crear YAGNI (no ho necessitaràs).
- Fes la feina més senzilla que sigui funcional.
- No em facis pensar.
- Escriu el codi per qui l’haurà de mantenir.
- El principi de la mínima sorpresa.
- Minimitzar l’acoblament i maximitzar la cohesió.
- Amagar els detalls de la implementació.
- La llei de Demeter: el codi només s’ha de comunicar amb les seves relacions directes.
- Evitar la optimització prematura: només si funciona i es lent.
- Reutilitzar codi és bo: el fa més llegible.
- Separació d’interessos: àrees de diferents funcionalitats han de tenir pocs solapaments.
- Els usuaris d’una classe han de dependre de la seva interfície pública, però la classe no ha de dependre dels usuaris.
Principis de POO (SOLID)
- Responsabilitat única (SRP): un component de codi ha de fer una sola feina i ben definida. Només caldrà modificar-lo si necessitem canviar aquesta feina. Això millora la cohesió i redueix possibles errors. Code smell: quan vull canviar una funcionalitat, una altra no relacionada queda afectada, i cal refer-la.
- Obert/tancat: les entitats software han d’estar obertes a ser esteses i tancades a ser modificades. Si cal estendre la funcionalitat és millor afegir codi que canviar l’existent. Això es pot fer amb abstracció, derivant classes i utilitzant polimorfisme, i amb encapsulació. Code smell: quan vull afegir funcionalitat, es produeix una cascada de canvis.
- Substitució Liskov: qualsevol classe que hereta d’una altra (pare) pot ser utilitzada d’igual forma que la pare sense conèixer les diferències entre elles. Per tant, quan heretem no hem de canviar el comportament que defineix la classe pare.
- Segregació d’interfície: es millor tenir moltes interfícies de client específiques que una sola de propòsit general. Així, evitem que els clients depenguin de mètodes que no utilitzen.
- Inversió de dependència: les dependències han de ser sobre abstraccions, no sobre concrecions. Es resumeix en dues qüestions:
- Els mòduls d’alt nivell (més abstractes) no han d’importar res de mòduls de baix nivell (més concrets). Els dos han de dependre d’abstraccions (p. ex. interfícies).
- Les abstraccions no han de dependre dels detalls. Són els detalls (implementacions concretes) les que han de dependre de les abstraccions.
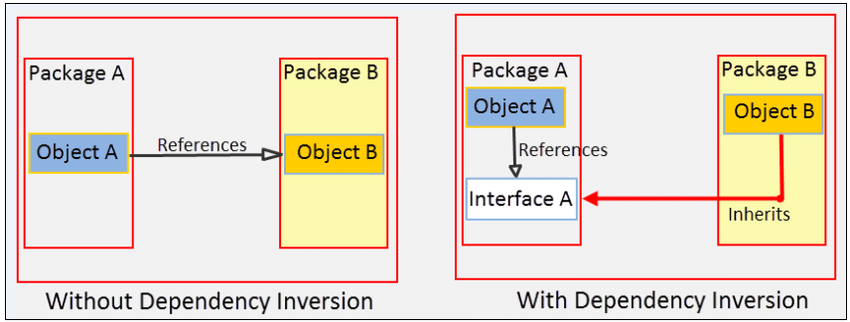
Dependències a POO
A POO, si tenim dues classes A i B, i A necessita a B per fer la seva feina, llavors A té una dependència de B. Per a resoldre aquesta dependència podem fer:
- Que A crei o obtingui un un objecte B. La classe A té el control de la dependència.
- Que B rebi un objecte B. Algú altre li proporciona, sense que A s’hagi de preocupar.
A més, quan necessitem un objecte poden passar almenys dues coses:
- Que necessitem una nova instància cada cop. Per exemple, les factories creen múltiples objectes.
- Que necessitem una única instància compartida. Aquesta situació es relaciona amb el patró singleton.
La inversió de control (IoC) és un principi de POO que cedeix a un contenidor o framework la tasca de controlar la creació d’instàncies d’objectes.
Tenim principalment dues formes d’implementar IoC:
- L’injecció de dependència (DI), on un contenidor pren el control i fa crides al nostre codi per proporcionar les dependències d’un objecte. Hi ha principalment dos tipus: de construcció i de setter.
- El Service Locator, que introdueix un nou objecte al nostre codebase, el Locator, que permet resoldre dependències d’una certa classe.
Aquestes tècniques es poden implementar per a subministrar instàncies úniques o múltiples. Per a permetre instàncies úniques, com serveis, utilitzen un mapa o diccionari d’instàncies accessibles pel nom de la classe.
L’objectiu d’aquestes tècniques és seguir el principi d’inversió de dependència: fem les dependències sobre abstraccions (interfícies). Això permet separar l’ús de la construcció, i podem substituir les implementacions sense afectar el codi.
Arquitectura i fronteres
Definició de frontera
L’arquitectura d’un sistema defineix com es divideix en components, quines són les fronteres o límits (boundaries) d’aquests components i com es comuniquen a través d’aquestes. Quan no hi ha fronteres parlem del monòlit.
El propòsit d’aquestes fronteres és facilitar el seu desenvolupament, gestió, manteniment i evolució. Una bona definició de les fronteres redueix l’acoblament, facilitant la flexibilitat de modificar unes parts sense afectar unes altres, i evita la degradació gradual de l’arquitectura. D’això se’n diu arquitectura evolutiva.
- Facilita el desenvolupament, perquè permet desenvolupar les parts de forma independent, a ritmes diferents.
- Facilita les proves, podem crear objectes que simulen comportament (test doubles), com dummies, stubs, mocks o fakes.
- Facilita els canvis i l’evolució, ja que podem canviar la implementació d’un comportament sense afectar la resta.
Les dependències entre components haurien de ser un graf acíclic dirigit. Això evita les dependències circulars, que augmenta l’acoblament dels components i limita la possibilitat de reutilitzar-los de forma individual.
Tipologia de fronteres
Tenim dos processos per a crear fronteres: separació horitzontal i vertical.
- L’horitzontal crea les fronteres entre àrees tècniques del sistema. Per exemple, una API, la lògica de negoci i la comunicació amb la base de dades. Els canvis impliquen habitualment diferents capes del sistema. Pot ser un problema si les capes les gestionen diferents equips de desenvolupament.
- La vertical crea la frontera entre àrees funcionals del sistema. S’utilitza amb microserveis. Per exemple, la gestió d’usuaris o la creació de comandes. Els canvis en aquest tipus de separació són més àgils.
Les fronteres poden combinar aspectes horitzontals i verticals i utilitzar diferents mecanismes de separació:
- Codi font: utilitzant classes i interfícies per poder comunicar-se mitjançant mètodes sense veure la implementació. Si es fa bé (actuant amb bona fe), permet aïllar les parts per permetre múltiples equips treballant. És l’únic mecanisme dels monòlits.
- Components vinculats dinàmicament: es fa una separació amb components desplegables, per exemple, arxius JAR. Es comuniquen amb crides a mètodes, i poden utilitzar el principi d’inversió de dependència per a establir les relacions entre ells.
- Processos locals: tenim processos locals que estan a la mateixa màquina. Poden comunicar-se utilitzant memòria compartida o sòcols. Permeten utilitzar diferents entorns de desenvolupament i tecnologies, sempre que es comparteixi el protocol.
- Serveis: permet que els serveis estiguin a diferents màquines i utilitzin la xarxa. No se sol compartir la base de dades (mala pràctica). S’estableixen protocols estàndards basats en la xarxa, com REST. Exemple dels microserveis.
Els dos primers mecanismes es basen en la definició d’interfícies i els altres dos en la definició de protocols.
Disseny per contracte
La correcta definició de la frontera és essencial. El disseny per contracte és una forma de dissenyar formalment les interfícies dels components d’un software respecte de qui els crida, o clients. Aquest contracte té dues parts:
- Els requisits que demana el component als clients.
- Les promeses fetes pel component als clients.
Resumint, si el client compleix els requisits, el component promet complir el contracte que defineix.
Si canviem un contracte, volem que els clients no quedin afectats. Per assegurar-nos utilitzem la frase “no requerir més ni prometre menys”: si el canvi no requereix més dels clients ni promet menys, la nova especificació es compatible i no trencarà el funcionament del client.
Algunes pràctiques per a seguir el disseny per contracte:
-
Documentar el contracte amb comentaris, responent quins són els requisits i les promeses que es fan. En resum, explicant exactament què es fa sense haver de saber com. A Java es fa al javadoc de la classe i dels mètodes públics.
-
Validar arguments dels mètodes i constructors públics. És raonable no fer-ho amb els privats, ja que només es criden per la mateixa classe. D’això també se’n diu precondicions. A Java, aquesta validació sol produir excepcions unchecked com IllegalArgumentException, NullPointerException o IllegalStateException que no cal obligatòriament documentar.
-
Validar les promeses que fa un mètode al seu client. D’això també se’n diu postcondicions. Per exemple, comprovar valors, tipus de retorn, errors i excepcions que es produeixen. Es pot fer just abans d’acabar un mètode públic.
-
Validar l’estat de l’objecte. D’això també se’n diu invariants de classe. Implica mantenir una sèrie de condicions sobre l’estat entre les crides a mètodes públics. Si l’objecte és immutable, només cal validar l’estat al constructor. Si és mutable, a cada mètode que canvia l’estat.
-
Opcionalment, aspectes sobre el rendiment (temps i espai).
Patrons d’arquitectura
L’arquitectura hexagonal és un patró arquitectural que permet separat el core de negoci (o domini) de la infraestructura (UI, base de dades, APIs, frameworks, etc.). Ho fa proposant els adaptadors i els ports.
Els adaptadors fan la interacció de la nostra aplicació cap al món. Tenim dos tipus:
- Els primaris: puts d’entrada de l’aplicació, operats principalment pels usuaris (UI, API Rest, CLIs).
- Els secundaris: actors secundaris com les bases de dades o serveis de tercers.
Si volem seguir el principi d’inversió de dependència, les capes internes no poden dependre de les externes. O sigui, les dependències han de ser de fora a dins: dels adaptadors cap al core.
Els ports són fronteres abstractes a l’exterior, per exemple, utilitzant interfícies, i els adaptadors són implementacions concretes dels ports, habitualment injectades:
- Els adaptadors primaris depenen de ports d’entrada, i dirigeixen l’aplicació (API, GUI, CLI).
- Els adaptadors secundaris implementen ports de sortida, i són dirigits per l’aplicació (BBDD, API clients).
DDD (Domain-drive design) és una estratègia de disseny de software focalitzat en el modelatge del software, i que té l’objectiu de replicar una àrea temàtica o domini (domain) gràcies als coneixements dels experts d’aquesta àrea.
Dins del DDD hi trobem diversos tipus de models, com les entitats, que tenen identitat, o les value objects, objectes immutables sense identitat. També hi ha aggregates, que són altres models dirigits per una entitat arrel.
L’arquitectura clean afegeix el concepte d’entitats i casos d’ús al core. Les dues es basen en el DDD. Les capes que defineix, de més interna a més externa són:
- Les entitats: objectes de negoci amb comportament
- Els casos d’ús (use cases): mapejat de la funcionalitat de les user stories
- Els adaptadors de interfícies (controladors, vistes, presentadors)
- Els frameworks i eines (BBDD, serveis de tercers)
En general, cap capa interna hauria de dependre d’una externa. Així és com queden:
- Sense dependències:
- Les entitats no depenen de ningú.
- Dependències cap a dins:
- Els casos d’ús depenen de les entitats.
- Els adaptadors d’entrada depenen dels casos d’ús.
- Dependències cap a fora, però abstractes (inversió de dependència):
- Els casos d’ús depenen dels adaptadors de sortida.
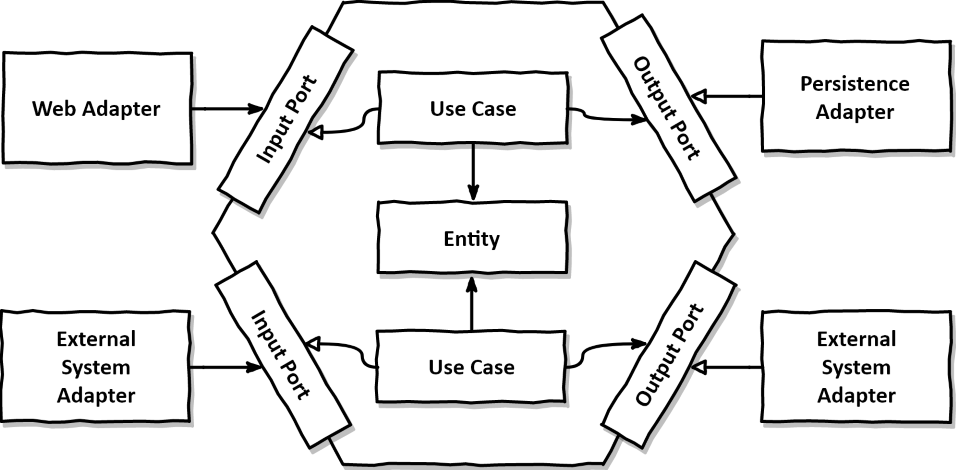
El diagrama mostra una arquitectura hexagonal amb conceptes DDD (clean). Les fletxes negres indiquen dependència d’una interfície i les blanques, implementació.
Cal no confondre la direcció de les dependències amb el flux de control. Per exemple, un flux de control d’una aplicació MVP podria ser controlador => cas d'ús => entitats => cas d'ús => presentador.
Finalment, cal dir que el cablejat dels components de l’arquitectura es fa des de fora de l’aplicació, creant les dependències, connectant-les i iniciant l’aplicació. Això es fa utilitzant el patró composition root. Aquí sol utilitzar-se la injecció de constructor i, si hi ha contenidors que fan inversió de control, és l’únic lloc on haurien d’aparèixer.
Diagrames d’arquitectura
El model C4 és un model que permet visualitzar l’arquitectura d’una solució. Descriu quatre nivells de diagrames, de més generals a més concrets:
- De context de sistema: mostra el sistema software i el seu context al voltant.
- De contenidor: mostra els contenidors dins d’un sistema software i com es relacionen.
- De component: mostra els components d’un contenidor i les seves interaccions.
- De codi: mostra la implementació del codi amb diagrames UML, diagrames ER o similars.
Hi ha quatre abstraccions que poden aparèixer en el nostre diagrama:
- La persona: actors o rols d’un sistema software.
- El sistema software: el sistema que estàs modelant, i que es relaciona amb altres sistemes externs.
- Un contenidor: una aplicació o un magatzem de dades. Per exemple:
- Un backend web
- Un frontend web
- Una aplicació desktop (client)
- Una app mòbil
- Una aplicació de consola o script
- Una funció serverless (cloud)
- Una base de dades
- Un magatzem al núvol
- El sistema d’arxius
- Un component: grup de funcionalitats encapsulada darrere d’una interfície (o contracte). Tots els components d’un contenidor solen executar-se en el mateix espai de processos o màquina virtual.
Alguns consells per a dibuixar diagrames:
- No hi ha una forma estàndard de fer-ho.
- Han de reflectir la realitat. Abstraccions primer, notació després.
- Conté blocs per als diferents components (SoC). Alguna cosa modular amb una interfície/fronteres. Els components contenen codi.
- Agrupar els components que treballen junts amb caixes (contenidors): DB schema, app mòbil, backend server-side app, console app, windows service.
- Ha d’incloure les dades, la lògica de negoci i la interfície d’usuari.
- Fletxes sempre direccionals per indicar la direcció del flux (petició) amb descripció.
- No cal afegir respostes (fletxes de tornada) dient OK, només qui les origina.
- Ser consistent en forma i color, evitar acrònims no coneguts.
REST APIs
Criteris de disseny
- Identificar els recursos que són part de l’API i els seus IDs.
- Definir l’URL del recurs, o també anomenades endpoints. Utilitzen noms (no verbs).
- Quan es retorna un sol recurs es retorna informació completa. Quan es retornen col·leccions se sol reduir la informació a l’estrictament necessària.
- Assignar els mètodes adequats.
Mètodes
El content type a utilitzar amb les peticions és “application/json”. Usos dels mètodes HTTP:
- GET recupera una representació del recurs a l’URI especificat.
- Si es troba, 200 (Ok). El cos del missatge de resposta conté els detalls del recurs sol·licitat.
- Si no es troba, 404 (Not Found).
- També es pot retornar 204 (No Content) si ha anat bé, però no es retorna cap contingut.
- Si les dades enviades no són vàlides, 400 (Bad Request). El cos pot incloure informació addicional sobre el problema.
- POST crea un recurs nou a l’URI especificat. El cos del missatge de sol·licitud proporciona els detalls del nou recurs. Tingueu en compte que POST també es pot utilitzar per activar operacions que en realitat no creen recursos.
- Si es crea un nou recurs, 201 (Created). El recurs pot retornar-se al cos.
- Si es fa algun procés, però no es crea res, 200 (Ok). El cos pot incloure el resultat de l’operació. Alternativament, si no hi ha resultat, es pot retornar 204 (No Content) sense cos.
- Si les dades enviades no són vàlides, 400 (Bad Request). El cos pot incloure informació addicional sobre el problema.
- PUT crea o substitueix el recurs a l’URI especificat. El cos del missatge de sol·licitud especifica el recurs que s’ha de crear o actualitzar.
- Si es crea un nou recurs, 201 (Created).
- Si s’actualitza, 200 (Ok) o 204 (No Content).
- Si no es possible l’actualització, 409 (Conflict).
- PATCH realitza una actualització parcial d’un recurs. El cos de la sol·licitud especifica el conjunt de canvis que cal aplicar al recurs. Les respostes podrien ser com les de PUT.
- DELETE elimina el recurs a l’URI especificat.
- Si funciona, 204 (No Content), sense retornar cap informació.
- Si es retorna alguna informació també es pot utilitzar 200 (Ok).
- Si no existeix, 404 (Not Found).
Aquests són alguns exemples d’endpoints i com se solen utilitzar segons els mètodes:
| Recurs | POST | GET | PUT | DELETE |
|---|---|---|---|---|
| /customers | Crear un nou client | Obtenir tots els clients | Actualitzar tots els clients | Esborrar tots els clients |
| /customers/1 | N/A | Obtenir els detalls del client 1 | Actualitzar els detalls del client 1, si existeix | Esborrar client 1 |
| /customers/1/orders | Crear una nova comanda per al client 1 | Obtenir totes les comandes del client 1 | Actualitzar totes les comandes del client 1 | Esborrar totes les comandes del client 1 |
Bones pràctiques
- Utilitzar JSON com a format per a enviar i rebre dades (cos)
- Utilitzar noms en lloc de verbs per als endpoints
- Els endpoints de col·leccions s’han d’anomenar amb noms plurals
- Envia codis d’estat per a gestionar els errors
- Utilitza filtres, ordenació i paginació a les dades
- Genera una bona documentació de l’API (OpenAPI)
Filtres, ordenació i paginació
Quan s’exposa un conjunt de recursos a un endpoint, cal evitar retornar una quantitat molt gran de dades. L’API hauria de permetre especificar filtres a l’URL: recursos?filtre1=valor1&filtre2=valor2…. També caldria especificar a l’URL com obtenir només una part dels resultats, quan poden ser molts.
L’ordenació també es pot realitzar amb un paràmetre del tipus recursos?order_by=criteri.
Cal utilitzar paginació sempre que una col·lecció de recursos pugui ser gran perquè pugui créixer sense límit. Es pot fer principalment de tres formes:
- offset:
recursos?limit=nombre&offset=nombrepermet utilitzar els paràmetres SQL per limitar els resultats. L’opció més senzilla, però poc òptima per a offsets alts: cal obtenir tots els registres anteriors en la query. - keyset: filtra pel valor d’un camp que defineix l’ordre. Per exemple, la data de creació. Podem utilitzar
recursos?limit=nombre&from_date=data. - seek: similar a l’anterior, però utilitzant una primary key. Podem utilitzar
recursos?limit=nombre&after_id=id.
Per a la paginació, pots utilitzar un valor de límit per defecte si no es diu res. Per exemple, 20. No s’hauria de permetre un valor qualsevol per a aquest paràmetre (ha d’estat limitat). També pots retornar informació al cos de la resposta que pugui ajudar al client a gestionar el resultat.
Referències
- The C4 model for visualising software architecture
- PlantUML
- UML diagrams with plantUML
- Inversion of Control Containers and the Dependency Injection pattern
- Best Practices for Designing and Implementing a Library in Java
- Dependency injection
- Software Architecture Boundaries
- Acyclic Dependencies Principle
- Top 20 Design Heuristics
- Design Principles (Bob Martin)
- Listing of Arthur Riel’s heuristics
- Design by Contract
- Hexagonal architecture
- The Clean Architecture
- Hexagonal Architecture with Java and Spring
- Domain-centric Architectures (Clean and Hexagonal) for Dummies
- RESTful web API design
- REST API Design: Filtering, Sorting, and Pagination
- What is REST
- OpenAPI